5.1 Werkinstructies
Werkinstructie SIM omzetten naar UGM
- Kopieer de SIM-package vanuit het KING:SIM-project naar het KING:UGM-project (‘Full structure for duplication’);
- Voer het ‘Set traceability’ script uit. Ga voor een beschrijving daarvan naar de sectie ‘Set traceability script draaien’ op deze wiki-pagina en kies voor de variant ‘Set traceability with transformation’ (het onderliggende metamodel voor SIM moet immers omgezet worden naar een metamodel voor het UGM);
- Volg vervolgens de beschrijving in 4.2 Het opstellen van een horizontaal GegevensUitwisselingsModel.
Werkinstructie UGM omzetten naar BSM
Noot Robert: Volgens mij zijn er 2 verschillende manieren om een BSM te vervaardigen. Helemaal handmatig waarbij de onderstaande procedure wordt gebruikt of half geautomatiseerd waarbij de Berichtengenerator wordt gebruikt. klopt dat?
- Kopieer het UGM-package vanuit het KING:UGM-project naar het KING:BSM-project (‘Full structure for duplication’);
- Voer het ‘Set traceability’ script uit. Ga voor een beschrijving daarvan naar de sectie ‘Set traceability script draaien’ op deze wiki-pagina en kies voor de variant ‘Set traceability without transformation’ (ook in het BSM gebruiken we immers het metamodel voor het UGM);
- Volg vervolgens de beschrijving in Opstellen van een koppelvlak-BerichtStructuurModel
Werkinstructie UML-package in subversion zetten
- Rechtermuisklik op package
- Ga naar Package control / Configure
- Check het vinkje Control Package
- Selecteer de gewenste version control locatie
- Klik op OK
Werkinstructie Nieuwe versie Semantisch Informatiemodel IN SVN zetten
SIM’s worden tijdens het opstellen niet opgeslagen in subversion omdat dit het tegelijkertijd met meerdere personen werken aan een Enterprise Architect bestand zou beletten. Om die reden moet nadat een SIM is vrijgegeven voor verdere verwerking deze eerst in versiebeheer ondergebracht worden. Hoe gaat dit echter in zijn werk (er van uitgaand dat een eerdere versie van het SIM al in beheer is in subversion)?
- Open het EA bestand;
-
Klik met de rechtermuistoets in de Project Browser op het SIM package dat je wil overzetten en kies ‘Import/Export Export package to XMI file…’. Let op het moet wel XMI versie 1.1 zijn; - Sla het bestand op over het oude XMI bestand in de folder waarin je de in subversion beheerde XMI standen hebt staan;
- Sluit het EA bestand;
- Ga in bestandsbeheer of vergelijkbaar tool naar het betreffende bestand en voer vervolgens bijvoorbeeld m.b.v. Tortoise een commit uit.
Het bestand is nu weer te gebruiken in een onder controle van subversion staande omgeving. Vergeet echter niet om in EA op het package een ‘get Latest’ te doen.
Overdragen van een model naar het GEMMA platform
Om de catalogus op het GEMMA platform te genereren is een bestand nodig dat Imvertor maakt. Dit bestand bevat alle informatie die nodig is. Het bestand zit in de ZIP van de release, die je vanuit EA of vanuit het dashboard kunt ophalen. Het bestand zit in:
etc/system.imvert.xml
Geef het ZIP bestand door aan
Toine.Schijvenaars@vng.nl
Dit is voorlopig de manier om de overdracht te realiseren; er wordt nagedacht of en hoe we dit volautomatisch kunnen laten verlopen.
Werkinstructie Runnen van Imvertor
20160824 Eerste kennismaking met Imvertor vanuit EA
Voor de early adapter van KING en Kadaster. Let op: het is nog steeds wel beta software. De samples bevatten ook enkele foutjes. Extra leuk om mee te werken. Ook wordt nog de volledige gebruikersdocumentatie opgeleverd door Geert Bellekens.
Download en installeer de msi: EAToolPack_Setup_v*.msi (of via de site van Geert: https://bellekens.com/)
Open EA op een van deze voorbeelden. Ga naar Extensions| EA imvertor | Settings
Kies voor KING het volgende:
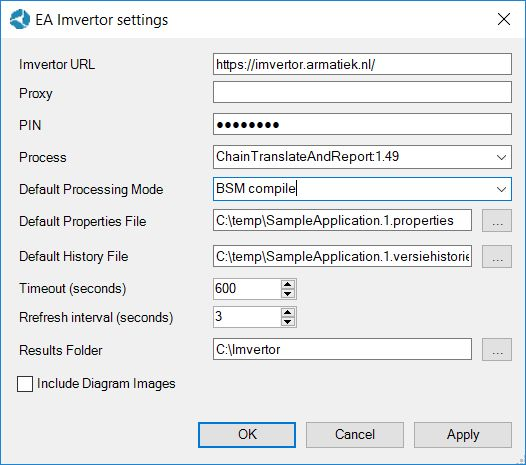
De velden ‘Default Processing Mode’ en ‘Default properties File’ kunnen voor jou natuurlijk een andere waarde krijgen. De laatste kan zelfs leeg blijven. Verder bepaal je natuurlijk zelf waar je results opgeslagen moeten worden.
Ga nu naar je project, en plaats cursor op een basismodel of een applicatie of een koppelvlak. Kies rechter muisknop Extenstions | EA imvertor | Publish to imvertor, of kies in het Add-in window dat open gaat voor “Publish”. Pas eventueel de settings aan, en kies ok. Laat Imvertor lopen. Als klaar zie je “Finished (…)”. Loop de knopjes na onderin het scherm, in het Add-in window. Kijk eens rond. Ga ook eens via knop Messages naar een message, en kies rechter muisknop | Find in project browser (of alt-G). Details worden later via documentatie bekend gemaakt. Functionele suggesties graag via Redmine of Jira opvoeren onder issue titel “IMVERTOR SERVER: ……”.
Werkinstructie vergelijken (comparing) van modellen
Het vergelijken van de modellen kan op 2 verschillende manieren.
- Het vergelijken met een andere versie van hetzelfde model. Je vergelijkt dan op release;
- Het vergelijken met een ander model. Je vergelijkt dan op supplier en dus altijd met iets wat hoger in de modellen-hiërarchie staat.
De huidige interface van imvertor binnen Enterprise Architect biedt geen mogelijkheden om deze keuzes te maken reden waarom je zelf zult moeten voorzien in een parameter bestand. Een parameter is een simpel text bestand dat je (bijv. in notepad) aanmaakt met de volgende parameters als inhoud:
- compare, deze heeft de waarde ‘release’ of ‘supplier’;
- comparewith, deze is alleen van toepassing als de parameter ‘compare’ de waarde ‘release’ heeft.
Zo worden deze parameters gedefinieerd in het parameter bestand (voorbeeld):
compare = release
comparewith = 20160901
Bewaar dit bestand waar je het later eenvoudig kunt vinden.
Een vergelijking op een ‘supplier’ wordt altijd uitgevoerd vanuit de laagste laag in hiërarchie, waarbij SIM hoger is dan UGM en UGM hoger is dan BSM. Er wordt altijd vergeleken met de release van de supplier die in de tagged-value ‘supplier-release’ van de laagste laag staat. Een BSM kan overigens niet met een SIM vergeleken worden.
Zorg er voor dat de versie of het suppliermodel waarop je wil vergelijken wel eerder door imvertor verwerkt is. Is dit niet het geval dan zul je dit nog moeten doen. In dat geval zou je via Tortoise eerst de betreffende versie van dat model uit subversion kunnen exporteren, zonder daarbij overigens de huidige werkbestand te overschrijven. Schrijf het bestand dus even weg op een andere plaats. Deze versie kun je vervolgens weer binnenhalen in een EA bestand en vervolgens verwerken met imvertor.
Is dat eenmaal gedaan dan ga je als volgt te werk:
- Kies in EA het package dat je wil vergelijken;
-
Kies rechter muisknop Extenstions EA imvertor Publish to imvertor, of kies in het Add-in window dat open gaat voor “Publish”; - Je krijgt nu het volgende scherm waarin je in het veld ‘Properties File’ het eerder door jezelf gemaakt properties bestand ophaalt. Zoals je ziet heb ik dat de naam ‘KING.compare.properties’ gegeven/
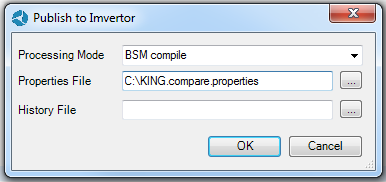
- Klik op ‘OK’ en in het resultaat kun je de verschillenlijst selecteren.
Het gebruik van Datatypes
We onderkennen binnen Enterprise Architect 3 niveaus waarop datatypes worden gedefinieerd:
- Primitieve datatypes;
- Generieke datatypes;
- Lokale datatypes.
In de volgende paragrafen wordt beschreven hoe je hiermee om gaat.
Primitieve datatypes
Primitieve datatypes zijn datatypes waarvan de vorm als bekend verondersteld mag worden maar die niet binnen onze modellen in Enterprise Architect worden gedefinieerd. Deze datatypes noemen we Primitieve datatypes alhoewel het niet persé alleen hoeft te gaan om de rudimentaire primitieve datatypes.
Primitieve datatypen staan gedefinieerd in het SIM package ‘MIM11 Primitieve datatypen’. Indien je in je EA bestand niet beschikt over dit datatype dan kun je dit ophalen in de subversion folder voor de SIM tags, het betreft het bestand ‘MIM 1.1 Primitieve datatypen R20201204.xml’.
Gebruik van de datatypes in dit package is redelijk eenvoudig. De datatypes kunnen in een SIM, UGM en BSM model aan een attribute gekoppeld worden middels een referentie in het type veld van dat attribute. Er wordt dus een referentie gemaakt naar een component in het externe SIM package (ook binnen een UGM en BSM model).
Beheer van Primitieve datatypes
Deze sectie bevat informatie die alleen voor beheerders van EA configuraties en Imvertor van belang is.
De informatie in deze paragraaf is erg technisch van aard en daarom vooral bedoelt voor de VNG Realisatie beheerders van Imvertor (Johan Boer en Robert Melskens).
De term ‘primitieve datatypes’ wordt eigenlijk niet zuiver gehanteerd in de MIM 1.1 standaard. Zo zou ‘URI’ bijvoorbeeld kunnen zijn afgeleid van ‘CharacterString’. Een betere naam zou zijn “Built-in types”:https://nl.wikipedia.org/wiki/Datatype#Primitief_type. Het gaat om types die je gratis krijgt bij de schematalen. Zo hoef je voor het kunnen gebruiken van de XML-Schema datatypes ‘xs:string’, ‘xs:int’, ‘xs:gYear’ en de yaml datatypes ‘string’, ‘integer’ en ‘number’, in XML-Schema en yaml niets te doen. Elke XML-Schema cq. yaml parser weet wat daarmee bedoelt wordt.
Omdat we onze UML modellen zoveel mogelijk schemataal agnostisch proberen te modelleren kennen onze modellen bijv. de genoemde XML-Schema datatypes niet. Daar maken we gebruik van schemataal agnostische types zoals ‘CharacterString’. Om deze datatypes binnen Imvertor toch op de juiste wijze te kunnen verwerken worden een aantal karakteristieken hiervan binnen Imvertor gedeclareerd in een zogenaamd conceptual-schema (‘conceptual-schemas.xml’). Een bestand waarin per schemataal een aantal metagegevens van het datatype kunnen worden vastgelegd. Om te weten dat en naar welk XML-Schema type het datatype vertaald moet worden moet Imvertor bijvoorbeeld weten dat het om een primitive type gaat en welk XML Schema type je daar dan precies voor moet gebruiken. Om het te verwerken in een OAS3 of RDF schema heb je echter wellicht hele andere waarden en mogelijk zelfs hele andere metagegevens nodig. Het gaat er in ieder geval om dat Imvertor weet in welke situatie hij op welke wijze moet refereren aan het primitieve datatype.
Op het moment dat bij het processen van een model een referentie naar een agnostisch datatype wordt gevonden wordt, omdat Imvertor nergens iets anders vindt over zo’n datatype, teruggevallen op de definitie van dat datatype in het conceptual schema.
Nu kun je binnen Enterprise Architect dit soort datatypes op 2 verschillende manieren op een property specificeren.
- door de naam hard in te geven in het ‘Type’ veld;
- door in het ‘Type’ veld een verwijzing te plaatsen naar een in een extern package gedefinieerd datatype.
Een voorbeeld van een package met dit soort datatypes is het package ‘MIM11 Primitieve datatypen’. Dit bevat de volgende MIM 1.1 primitieve datatypes:
- CharacterString
- Integer
- Real
- Decimal
- Boolean
- Date
- DateTime
- Year
- Month
- Day
- URI
Hoe deze datatypes in deze packages zijn gedefinieerd is niet van belang. De naam en evt. de identifier zijn van belang, niet het stereotype of enig andere karakteristiek. Zoals gezegd kan je, om een van deze datatypes te gebruiken, er naar refereren door in het ‘type’ veld het betreffende datatype hard in te geven. Het heeft echter de voorkeur er naar te refereren door in het ‘type’ veld een van de types uit de packages ‘MIM11 Primitieve datatypen’ te selecteren. Die manier van werken willen we zelfs binnen VNG-Realisatie standaard gaan toepassen.Om die laatste methode af te dwingen is het gebruik van de parameter ‘nativescalars’ met de waarde ‘no’ van belang. Het hard ingeven van een datatype in het ‘Type’ veld is dan niet meer toegestaan. }}
Generieke datatypes
Binnen VNG Realisatie onderkennen we op dit moment 2 verschillende packages met generieke datatypen:
- het package met de gemeentelijke generieke datatypen;
- het package met de gml generieke datatypen.
De gemeentelijke generieke datatypen staan gedefinieerd in het SIM package ‘Generieke Datatypen Gemeenten’ en de gml generieke datatypen in het SIM package ‘GML3’. Deze packages bevatten datatypes die gebaseerd zijn op de in de voorgaande paragraaf beschreven primitieve datatypes of op andere datatypes binnen ‘Generieke datatypes’ en ‘GML3’. Ze bevatten echter een aanscherping, bijv. d.m.v. een patroon, minimale lengte of minimale waarde. Dit zijn datatypes waarvan we verwachten dat ze binnen meerdere modellen een toepassing vinden. Denk aan ‘POSTCODE’, ‘YearMonth’, ‘NietNegatiefInteger’, ‘DMO’ en ‘DTMO’ maar ook ‘GM_Point’ en ‘GM_Polygon’.
Indien je in je EA bestand niet beschikt over het package ‘Generieke Datatypen Gemeenten’ dan kun je dit ophalen in de subversion folder voor de SIM trunk, het betreft het bestand ‘SIM_Generieke Datatypen.xml’.
Hiervoor zal nog een subversion tag worden aangemaakt waarna de tag gebruikt moet gaan worden.
Indien je in je EA bestand niet beschikt over het package ‘GML3’ dan kun je dit ophalen in de subversion folder voor de SIM tags, het betreft het bestand ‘SIM GML3 external in gebruik R20100128.xml’.
Ook het gebruik van generieke datatypen is redelijk eenvoudig. De datatypes kunnen in een SIM, UGM en BSM model aan een attribute gekoppeld worden middels een referentie in het type veld van dat attribute. Er wordt dus een referentie gemaakt naar een component in een van beide SIM generieke datatype packages (ook binnen een UGM en BSM model). Ook hier wordt dus een referentie gemaakt naar een extern package.
Beheer van Generieke datatypes
Deze sectie bevat informatie die alleen voor beheerders van EA configuraties en Imvertor van belang is.
De informatie in deze paragraaf is erg technisch van aard en daarom vooral bedoelt voor de VNG Realisatie beheerders van Imvertor (Johan Boer en Robert Melskens).
Naast dat de gemeentelijke generieke en gml datatypes zijn gedefinieerd in een UML model zijn ze ook in een extern schema gedefinieerd (bijv. XML-Schema of yaml). Het kan in dit geval gaan om complexe datatypes, groepen, enumeraties, referentielijsten, etc… Ook hier kan het weer gaan om verschillende schematalen al naar gelang waar behoefte aan is.
Wij hebben op dit moment alleen de packages ‘Generieke Datatypen’ en ‘GML3’ maar niets verhinderd ons om, als wij daar een goede reden voor hebben, andere packages en de daarbij horende schema bestanden te creëren. Op dit moment is daar echter nog geen reden toe.
De externe schema’s zouden op basis van de packages met generieke datatypen eveneens met Imvertor gegenereerd kunnen worden. Dat is echter bij ons niet het geval, voor nu hebben we ze handmatig vervaardigd en op een vaste via internet toegankelijke plaats opgeslagen. Zodra we echter wel van dat soort packages met Imvertor willen verwerken en er schema’s van willen genereren moeten ze natuurlijk weer voldoen aan dezelfde eisen als waaraan andere SIM packages moeten voldoen. We spreken echter af dat deze packages, ongeacht of ze wel of niet verwerkt worden met Imvertor, altijd voldoen aan deze eisen.
Let op! Op dit moment hebben we van zowel ‘Generieke Datatypen’ als ‘GML3’ ook nog ‘UGM’ en ‘BSM’ varianten. Deze zullen op korte termijn worden verwijderd.
Let op! Het package ‘Generieke datatypes’ in het ‘SIM’ project is nog van voor het MIM tijdperk. Dit model moet dus kritisch tegen het licht worden gehouden en worden aangepast aan de hierboven beschreven eisen, niet alleen qua metamodel maar ook qua primitieve datatypes waar de verschillende hierin gedefinieerde datatypes naar verwijzen.
Net als bij de ‘MIM 11 Primitieve Datatypen’ geldt ook hier dat alleen de naam van de componenten in het generieke model van belang is. Alle componenten die in het model gedefinieerd zijn moeten weliswaar correct zijn (zo kunnen ze als basis dienen voor een evt. lokaal datatype) maar voor de verwerking worden slechts de namen van de componenten gebruikt. Daarbij speelt ook hier het conceptual schema een rol. Alle in dit soort packages gedefinieerde datatypes moeten ook in het conceptual schema worden gedefinieerd zodat Imvertor weet dat het datatype in een ander schema gedefinieerd staat. In het geval generieke datatypen worden er in het conceptual schema geen schemataal specifieke gegevens opgenomen.
A.d.h.v. het attribute ‘//cs:Map/cs:forSchema/cs-ref:ConceptualSchemaRef/@xlink:href’ in het conceptual schema kan imvertor bepalen naar welk schema moet worden verwezen. Voorwaarde is wel dat de naam van het component in het ‘ Generiek datatype’ package exact gelijk is aan de naam van het gerelateerde component in het schema. De afspraak is dat de namen van deze datatypes alleen bestaan uit alfanummerieke karakters en underscores.
Let op! Voor de generieke datatypen gebruiken we op zowel SIM als UGM en BSM niveau hetzelfde package dat binnen het SIM project wordt geplaatst.
De volgende aanpassingen zijn n.m.m. nodig in de stylesheets:
- Andere organisaties dan VNG Realisatie moeten onafhankelijk van VNG Realisatie instellingen kunnen werken met generieke datatypen. Dat is op dit moment niet voor 100% mogelijk. Wel kunnen zij hun eigen ‘generieke datatype’ packages maken, hun eigen conceptual schema configureren, hun eigen externe schema aanmaken en aangeven waar dat schema gevonden kan worden. Zij zullen in het conceptual schema echter wel gebonden zijn aan het ‘id’ met de waarde ‘VNGR’ voor het element ‘cs:ConceptualSchema’. Een organisatie moet echter zijn eigen id kunnen definiëren zonder dat we daarvoor de stylesheet moeten aanpassen. Eigenlijk geldt zoiets soortgelijks voor de GML types. We zullen hiervoor een generieke oplossing moeten verzinnen;
- Als we het voorgaande probleem op de juiste wijze oplossen kunnen we voorkomen dat we de stylesheets ‘Imvert2OpenAPI-KING-endproduct-xml.xsl’, ‘EP-JSON.xsl’ en ‘EP-YAML.xsl’ aan moeten passen als we een andere generieke datatype package willen introduceren. Het moet dus redelijk eenvoudig mogelijk zijn een nieuw generiek datatype package te introduceren.
Lokale datatypes
Lokale datatypes worden altijd gedefinieerd binnen de folderstructuur van een SIM, UGM of BSM model. Het gaat hier om datatypes die gebaseerd zijn op de eerder behandelde primitieve datatypes of op datatypes binnen de lokale datatype package en een aanscherping bevatten. Toepassing van deze datatypes beperkt zich echter tot het model zelf. Lokale datatypes kunnen geen specialisatie van generieke datatypes zijn. Indien men een generiek datatype als basis wil nemen voor een lokaal datatype dan dient het generieke datatype gekopieerd te worden naar lokaal en daar verder worden aangescherpt.
Om deze datatypes correct te kunnen gebruiken moeten ze aan de onderstaande regels voldoen.
SIM Lokale datatypen:
- worden gedefinieerd in het basismodel waarin ze gebruikt worden;
- staan in een package van het MIM stereotype ‘Domein’;
- zijn van het UML type ‘Datatype’ of ‘PrimitiveType’ en hebben het MIM stereotype ‘Primitief datatype’;
- hebben een generalisatie naar een ander SIM lokaal datatype of een primitief datatype en bevatten tevens een aanscherping;
UGM Lokale datatypen:
- worden gedefinieerd in het basismodel waarin ze gebruikt worden;
- staan in een package van het MIM stereotype ‘Domein’;
- zijn van het UML type ‘PrimitiveType’ en hebben het MUG stereotype ‘Primitief datatype’;
- hebben een generalisatie naar een ander UGM lokaal datatype of een primitief datatype en bevatten tevens een aanscherping en hebben een trace naar een lokaal datatype op SIM niveau;
BSM Lokale datatypen:
- worden gedefinieerd in het koppelvlak waarin ze gebruikt worden;
- staan in een package van het MIM stereotype ‘Bericht’;
- zijn van het UML type ‘PrimitiveType’ en hebben het MUG stereotype ‘Primitief datatype’;
- hebben een generalisatie naar een ander BSM lokaal datatype of een primitief datatype en bevatten tevens een aanscherping en hebben een trace naar een lokaal datatype op UGM niveau.
Deze datatypes worden aan een attribute gekoppeld middels referentie naar het betreffende datatype.
Vraag De vraag is of we in UGM en BSM niet ook aan het UML type ‘Datatype’ het stereotype ‘Primitief datatype’ willen kunnen koppelen. In principe vind ik dat dat moet kunnen aangezien een datatype met aangescherpte definities geen PrimitiveType meer is. Ook het UGM stereotype ‘Primitief datatype’ klopt dan n.m.m. niet.
Het kan gebeuren dat we een datatype dat gedefinieerd is in een lokaal package ook in andere modellen willen gebruiken. Op dat moment moeten we zo’n datatype gaan definiëren in een package voor generieke datatypes. De procedure om dat te doen staat beschreven in de volgende paragraaf.
Het verheffen van een lokaal datatype naar een generiek datatype
Het kan voorkomen dat een lokaal datatype ook voor andere modellen van belang kan zijn. In dat geval moet het worden omgezet naar een generiek datatype. De procedure daarvoor is als volgt:
- Er wordt een verzoek gedaan (door de eigenaar van een model, een geïnteresseerde gebruiker of door het standaardisatieoverleg) een datatype te verheffen bij de beheerder van het generieke datatype package (Johan Boer of Robert Melskens). Daarbij wordt aangegeven in welk model het datatype gevonden kan worden;
- De beheerder kopieert het datatype 1 op 1 uit het SIM model naar het SIM ‘Generieke datatypen’;
- Hij zorgt er voor dat de met dat generieke datatypen model gerelateerde schema’s aangepast worden hetzij door het package met Imvertor te verwerken en het schema op de juiste locatie te plaatsen hetzij door de wijzigingen handmatig in het schema aan te brengen;
- Hij maakt een nieuwe tag aan van het gewijzigde generieke datatypen package;
- Hij brengt tevens alle benodigde wijzigingen aan in het conceptual schema;
- De beheerder stelt alle model ontwerpers op de hoogte van het bestaan van het nieuwe generiek datatype;
- De aanvrager past zijn model zo aan dat alle attributes die het oude lokale datatype gebruikten nu het datatype uit het generieke package gebruiken;
- Als hij alle attributes zo heeft aangepast verwijdert hij het datatype uit het interne datatype package;
- Andere gebruikers kunnen op dezelfde wijze ook gebruik maken van het nieuwe generieke datatype.